|
Haoge Deng I am an AI Algorithm Engineer at Alibaba’s ATH business group. Previously, I completed my MSc at BUPT (supervised by Prof. Yonggang Qi) and conducted research at CASIA and BAAI with Prof. Zhaoxiang Zhang and Dr. Xinlong Wang. My research interests include generative models , with a particular focus on world model and multimodal generation. |

|
ResearchRepresentative papers are highlighted. * indicates equal contribution, # indicates corresponding author. |
|
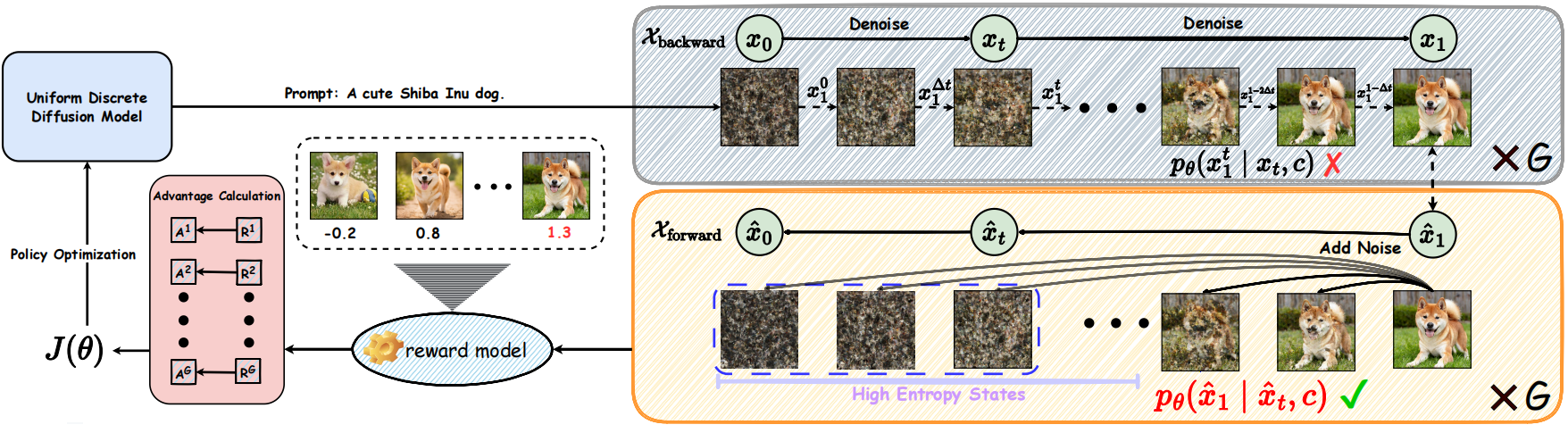
UDM-GRPO: Stable and Efficient Group Relative Policy Optimization for Uniform Discrete Diffusion Models
Jiaqi Wang*, Haoge Deng*, Ting Pan*, Yang Liu, Chengyuan Wang, Fan Zhang, Yonggang Qi#, Xinlong Wang# (ICML Spotlight), 2026 International Conference on Machine Learning (ICML, CCF-A), 2026 (Spotlight, ~2% acceptance rate) [arxiv] | [project page] | [code] UDM-GRPO is the first framework to integrate UDM with RL, which treats the final clean sample as the action for stable optimization and reconstructs trajectories via the diffusion forward process to significantly improve base model performance across multiple T2I tasks. |

|
Emu3.5: Native Multimodal Models are World Learners
BAAI [arxiv] | [project page] | [code] Emu3.5 is a natively multimodal world model that unifies vision and language through end-to-end next-token prediction on interleaved video-derived data, enhanced by reinforcement learning and DiDA-based parallel decoding for efficient, spatiotemporally consistent generation. |

|
Uniform Discrete Diffusion with Metric Path for Video Generation
Haoge Deng*, Ting Pan*, Fan Zhang*, Yang Liu*, Zhuoyan Luo, Yufeng Cui, Wenxuan Wang, Chunhua Shen, Shiguang Shan, Zhaoxiang Zhang#, Xinlong Wang# International Conference on Learning Representations (ICLR, CCF-A), 2026 [arxiv] | [project page] | [code] | [poster] [hugging face 🤗 daily papers] URSA is a simple yet powerful discrete framework that formulates video generation as an iterative process of global refinement over spatiotemporal tokens, enabling efficient scaling to long-duration videos. |
|
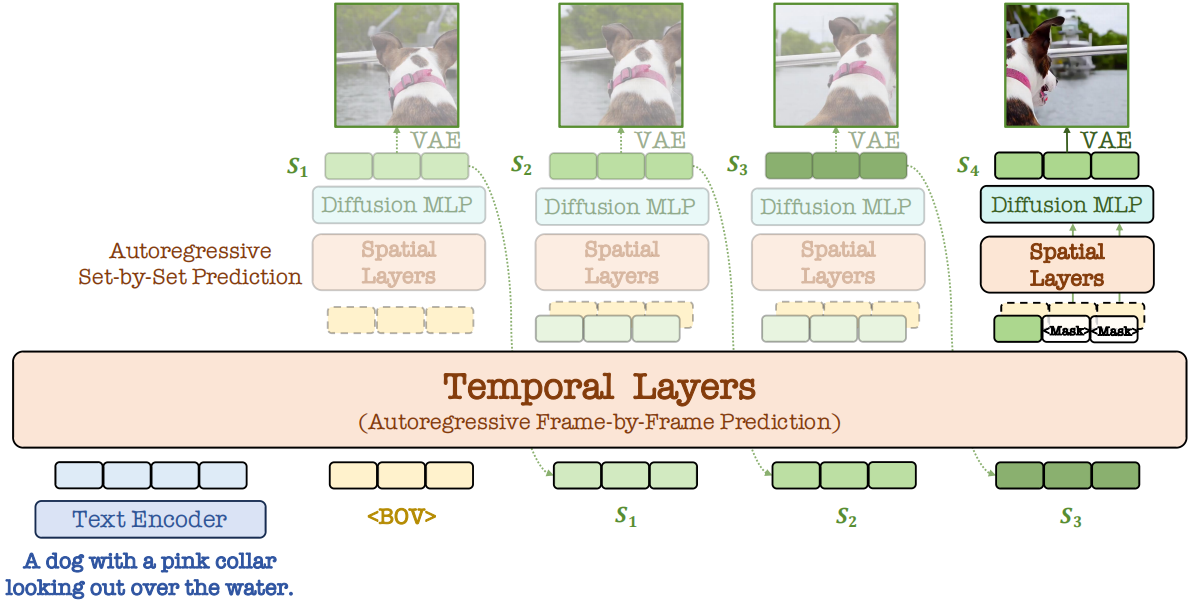
Autoregressive Video Generation without Vector Quantization
Haoge Deng*, Ting Pan*, Haiwen Diao*, Zhengxiong Luo*, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi#, Xinlong Wang# International Conference on Learning Representations (ICLR, CCF-A), 2025 [arxiv] | [project page] | [code] | [openreview] | [post] | [iclr poster] [hugging face 🤗 daily papers] NOVA is a non-quantized autoregressive model that enables efficient video generation by reformulating the video creation as frame-by-frame and set-by-set predictions. |
|
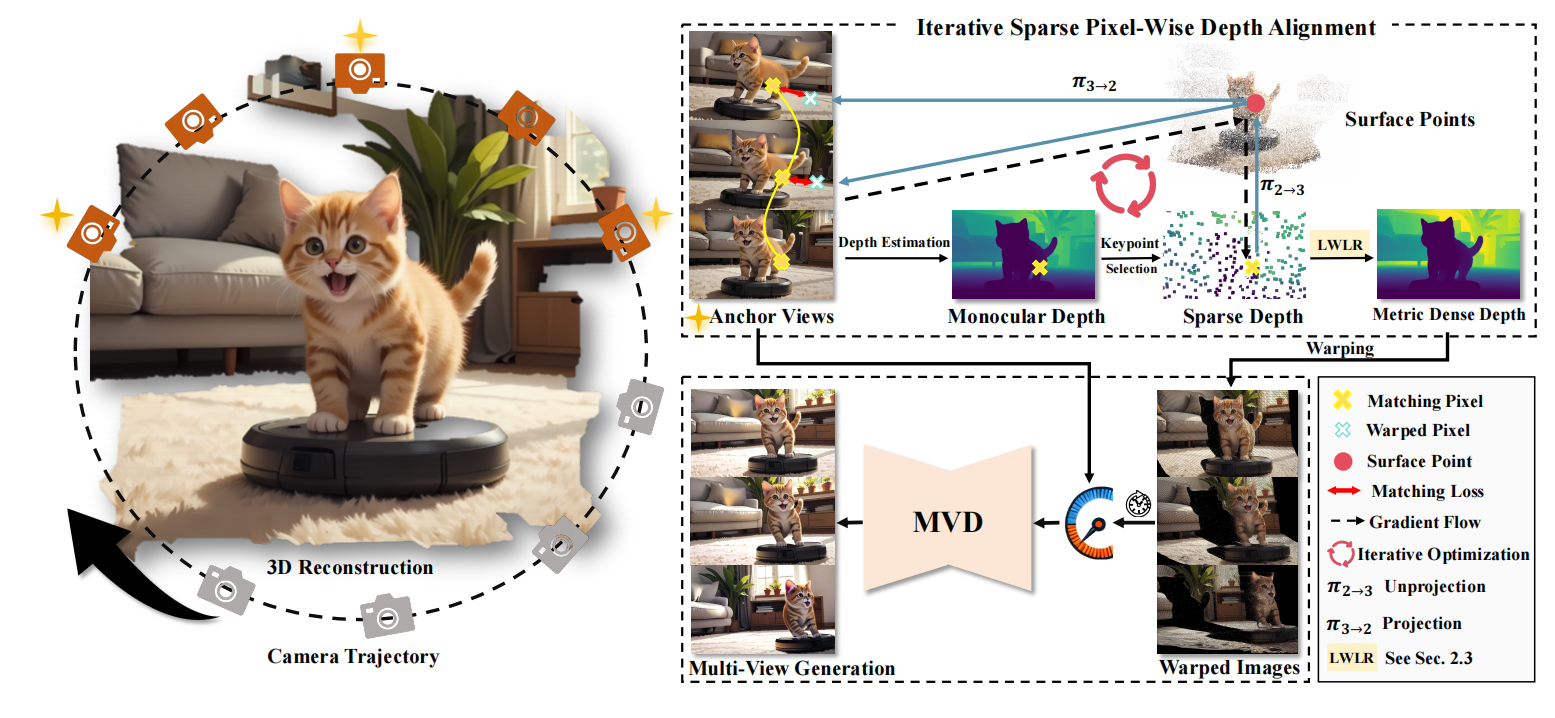
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at
Scale
Baorui Ma*, Huachen Gao*, Haoge Deng*, Zhengxiong Luo, Tiejun Huang, Lulu Tang#, Xinlong Wang# IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR, CCF-A), 2025 (Highlights, ~3% acceptance rate) [arxiv] | [project page] | [code] | [dataset] | [post] | [hugging face 🤗 daily papers] See3D is a scalable visual-conditional MVD model for open-world 3D creation, which can be trained on web-scale video collections without camera pose annotations. |
|
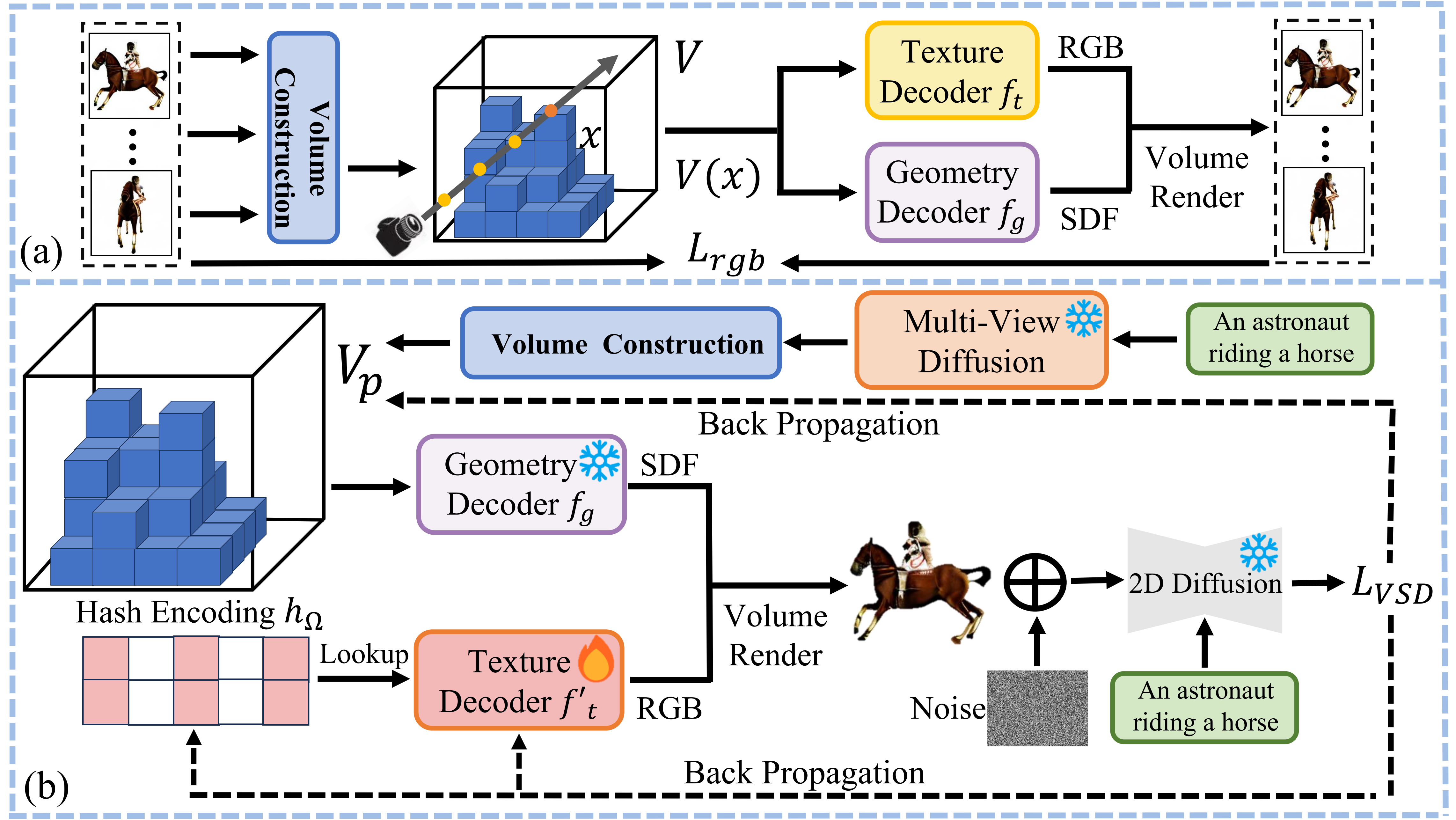
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and
Consistent 3D Generation
Baorui Ma*, Haoge Deng*, Junsheng Zhou , Yu-Shen Liu, Tiejun Huang, Xinlong Wang# arXiv, 2023 [arXiv] | [project page] | [code] GeoDream is a 3D generation method that integrates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. |
|
SketchKnitter: Vectorized Sketch Generation with Diffusion Models
Qiang Wang, Haoge Deng, Yonggang Qi#, Da Li, Yi-Zhe Song, International Conference on Learning Representations (ICLR, CCF-A), 2023 (Spotlight, ~5% acceptance rate) [paper] | [openreview] | [code] SketchKnitter is a method that achieves vectorized sketch generation by reversing the stroke deformation process using a diffusion model learned from real sketches, enabling the creation of higher quality, visually appealing sketches with fewer sampling steps. |
Education |

|
Research Experience in Generative AI collaborated with Prof. Zhaoxiang Zhang and Dr. Xinlong Wang Sep. 2025 ~ Feb. 2026 |

|
Master of Science in Artificial Intelligence Under the supervision of Prof. Yonggang Qi Sept. 2022 ~ July. 2025 |
|
|
Bachelor of Engineering in Electronics Engineering Outstanding Graduate of Beijing Province Sept. 2018 ~ July. 2022 |
Experiences |
|
|
Research Intern at BAAI-Vision Research on Video generation Advised by Dr. Zhengxiong Luo and Dr. Xinlong Wang Jun. 2024 ~ Now |
|
|
Research Intern at BAAI-Vision Research on 3D content generation Advised by Dr. Baorui Ma and Dr. Xinlong Wang Jun. 2023 ~ Jun. 2024 |
|
|
Research Intern at Meituan-AutoML Research on Lidar lidar range generation Advised by Dr. Zhi Tian and Dr. Xiangxiang Chu Jan. 2023 ~ Jun. 2023 |


Academic Services
|
|
|